반응형
Kafka 알아보기

Kafka란?
성능과 기능이 좋은 큐라고 할 수 있다.
주로 대량의 이벤트 스트림 데이터를 처리하고 여러 시스템 간에 데이터를 신속하게 전송하는 데 사용된다.
Kafka의 주요 특징
- 고성능: 초당 수백만 개의 메시지 처리 가능
- 확장성: 클러스터 형태로 노드를 추가하여 쉽게 확장 가능
- 내결함성: 노드 장애 시 자동 복구 가능
- 비동기 처리: 메시지를 보내고, 나중에 원하는 시점에서 처리 가능
- 이벤트 기반 아키텍처 지원: 마이크로서비스 간 메시지 교환 가능
Kafka의 핵심 구성 요소
📌 Producer
- 데이터를 생성하고 Kafka에 전송하는 역할
- 특정 Topic에 메시지를 보내며, 파티션을 지정 가능
- 프로덕션 중에 키를 보내는 것은 필수 X

📌 Broker
- Kafka 서버로서 Producer가 보낸 메시지를 저장하고 관리
- 여러 개의 Broker가 클러스터를 이루어 분산 저장 & 처리 (브로커끼리 연결하면 클러스터가 된다)
- 각 Broker는 여러 Topic과 Partition을 관리
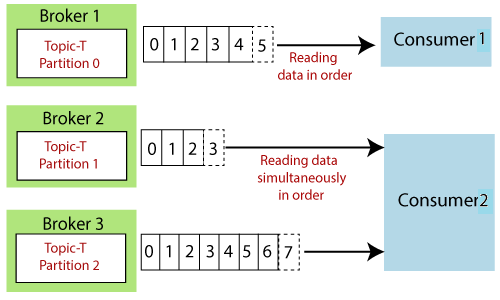
📌 Topic
- 메시지가 저장되는 단위
- Topic은 1개 이상의 Partition으로 구성
- 예) "reservation-events"라는 Topic이 있으면 예약 이벤트 저장
📌 Partition
- Topic을 여러 개의 Partition으로 나누어 병렬 처리 가능
- Kafka는 하나의 Partition을 하나의 Consumer에게만 할당
- Partition 내부의 메시지는 Offset을 기반으로 순서 보장 (단, 파티션 간 순서 보장은 안됨)
- 데이터는 유한한 시간 동안 저장 (기본값: 7일, log.retention.ms 설정 가능)
- Key가 없는 경우 Round-Robin 방식으로 랜덤 하게 할당
- Key가 있는 경우 Key 해시 기반으로 특정 Partition에 할당
- Partition 개수는 증가할 수 있지만, 감소는 불가능하여 처음 설계 시 신중하게 고려
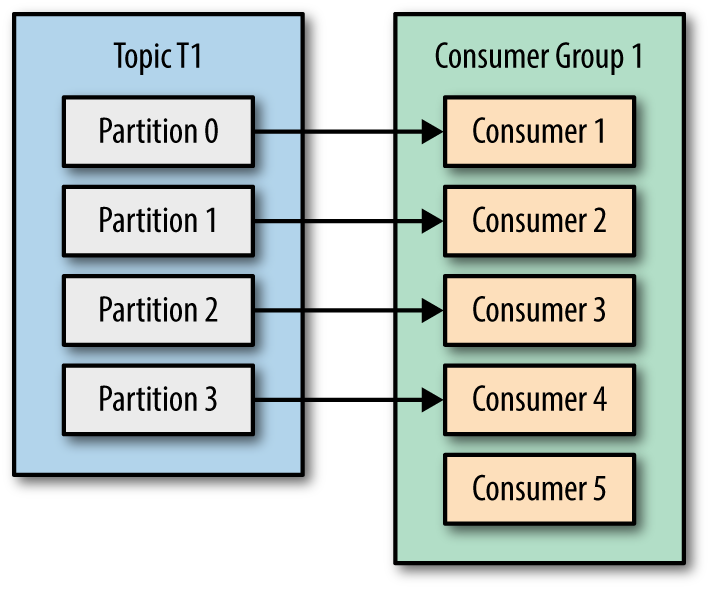
📌 Consumer
- Kafka에서 데이터를 읽어가는 서비스 (메시지를 소비하며 Offset을 유지해 처리 상태 관리)
- Consumer Group을 사용하면 여러 Consumer가 데이터를 병렬로 처리 가능
- 만약 Consumer 수가 Partition보다 많으면 일부 Consumer는 대기 상태

Kafka 리밸런싱 최적화
📌 리밸런싱이란?
Consumer 그룹 내에서 Partition을 재배치하는 과정
💡 리밸런싱이 발생하는 경우:
- Consumer 그룹의 Consumer 수가 변할 때 (추가/제거)
- Consumer에 네트워크 장애가 발생했을 때
- 특정 Consumer가 오랫동안 응답하지 않을 때
- Partition이 증가했을 때
Kafka는 리밸런싱을 통해 기존 Consumer가 할당받은 Partition을 새로운 Consumer에게 재할당한다.
그러나 리밸런싱 중에는 메시지를 소비할 수 없기 때문에, 빈번한 리밸런싱은 성능 저하를 유발할 수 있다.
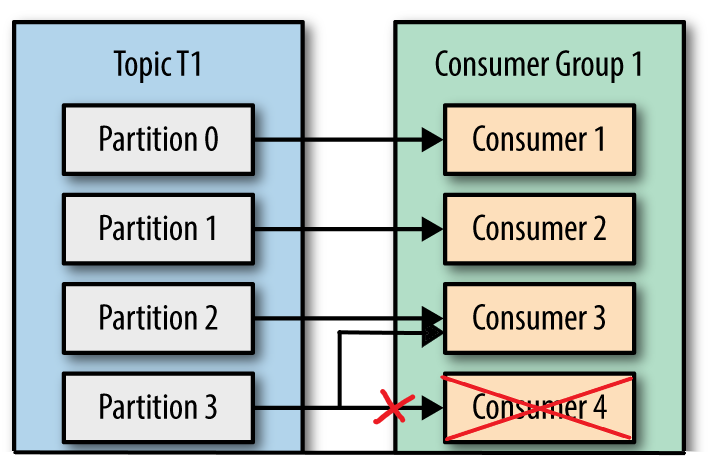
📌 리밸런싱 최적화 방법
1. Consumer 개수를 파티션 개수와 동일하게 맞추기
- Consumer 그룹 내 Consumer 개수를 Partition 개수와 동일하게 유지하면 불필요한 리밸런싱을 줄일 수 있다.
- Consumer 개수가 Partition보다 많으면 일부 Consumer는 대기 상태가 되어 비효율적이다
💡 Best : Consumer 수 = Partition 수
2. session.timeout.ms 값 조정하기
- Consumer가 일정 시간 동안 응답하지 않으면 Kafka는 Consumer를 죽은(dead) 상태로 판단하고 리밸런싱을 수행한다.
- 이 시간을 적절히 조정하면 불필요한 리밸런싱을 줄일 수 있다.
session.timeout.ms=45000 # 기본값: 45초 (설정 가능)
3. Static Membership 사용 (group.instance.id 설정)
💡 Static Membership이란?
- Consumer가 죽었다가 다시 실행되더라도 기존 Partition을 유지할 수 있도록 하는 기능
- Consumer가 다시 참여해도 Kafka가 이전 Partition을 그대로 유지하기 때문에 불필요한 리밸런싱을 줄여 성능을 최적화할 수 있다.
- 단기적인 장애 복구 시 매우 유용
spring:
kafka:
consumer:
group-id: my-consumer-group
properties:
group.instance.id: my-consumer-instance-1 # Static Membership 활성화
Kafka의 활용 사례
Kafka는 대량의 데이터를 빠르게 처리해야 하는 시스템에서 주로 사용된다.
📌 실시간 데이터 스트리밍
- 예시: 금융권에서 실시간 거래 내역을 수집하고 분석
- 고성능 데이터 전송으로 신속한 데이터 분석 가능
📌 로그 및 모니터링 시스템
- 예시: 서버 로그 데이터를 실시간으로 수집하여 분석 (ELK Stack과 연계)
- 장애 발생 시 빠르게 탐지하여 대응 가능
📌 이벤트 기반 아키텍처
- 예시: 마이크로서비스 간 주문 및 결제 이벤트 전달
- 서비스 간 결합도를 낮추고 확장성을 확보할 수 있음
📌 데이터 파이프라인
- 예시: 데이터베이스 변경 사항을 데이터 웨어하우스로 전송 (ETL 프로세스)
- 대량의 데이터를 안정적으로 전송하고, 중간 장애 발생 시 복구 가능
정리
Kafka 환경에서 리밸런싱은 필수적인 과정이지만 이를 최적화하면 성능 저하를 방지하고 안정적인 메시지 처리가 가능하다.
참고
https://medium.com/@cobch7/kafka-producer-and-consumer-f1f6390994fc
반응형
'CS > Spring' 카테고리의 다른 글
| 동시성 제어 방식 알아보기 (0) | 2025.02.02 |
|---|---|
| TDD 방법론 알아보기 (4) | 2024.12.29 |
| Spring Bean 알아보기 (0) | 2024.05.31 |
| DataSource 알아보기 (0) | 2024.03.31 |
| Connection Pool 이해하기 (3) | 2024.03.23 |



